Data
As of July 24, 2020, the dataset consists of 13,483 records of degrees conferred by the University of New Mexico between 1894 and 1959. The data was extracted from scanned documents in the UNM Archives, including:
- UNM course catalogs
- Board of Regents meeting minutes
- Faculty Senate meeting minutes
- UNM's yearbook, The Mirage
- UNM student newspapers
These scanned documents were processed using PDFMiner, Notepad ++, and MS Excel. Degree recipients' sex was coded based on first and middle names, and the presence of suffixes (Jr., II, III, etc.); if the names were ambiguous or unknown, the sex was coded as "U."
As of July 24, 2020, there are no plans to include more data in this dataset.
The dataset can be downloaded from UNM's Digital Repository.
One question that many people have asked about this project is, what about data on race and ethnicity for UNM graduates?
Unfortunately, the primary sources from which this data was extracted did not include this information in a form that could be easily converted into current terms. UNM's Office of Institutional Analytics has interactive data visualizations for degrees conferred in recent years (as well as statistics on enrollment, financial aid, and faculty & staff) on their web page.
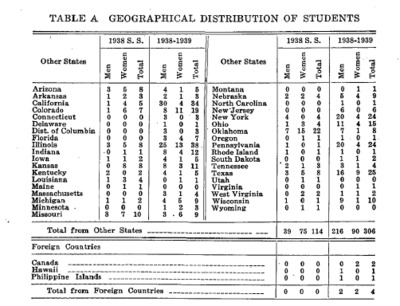
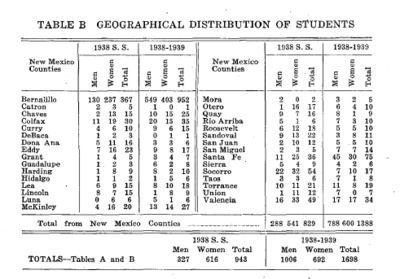
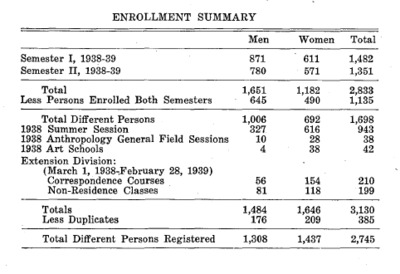
Available in the course catalogs in most of the years covered by our dataset are two tables of aggregate geographical data for currently enrolled students; Table A shows the distribution of students from US states and foreign countries in 1938, and Table B shows the distribution of students by New Mexico county. There is also an enrollment summary broken out by sex.
 |
 |
 |
Potential sources of error in the data:
1. The original lists of degree recipients were manually typed by various individuals beginning over 100 years ago, and their accuracy was not verified.
2. The sex of degree recipients was coded for this project based on first and middle names. These judgments could be in error in an unknown percentage of cases.
3. The optical character recognition of PDFs likely impacts the recorded spelling of recipient names, particularly surnames, in an unknown percentage of cases.
4. Mining of PDF data. Due to the script's interpretation of text block placement on pages, majors or minors could have been assigned to the wrong individual in an unknown percentage of cases.
Every effort was made to check for and correct these errors as far as possible. If you find data errors, please let us know and we will be happy to correct them and update our materials to reflect the changes.